I’ve recently been writing and thinking about polycentric urban regions, partly because I’m interested in how places connect (or not) for one of my research projects, and partly because I’ve been experimenting with ways to map the connections between places in polycentric urban regions. There was quite a lot of the latter in Peter Hall and Kathy Pain’s ‘
The Polycentric Metropolis’ from 2006 but given that the technology has moved on a little since then I thought I’d explore the topic in more detail. Mind you, I’ve also been looking back on Volumes 1 to 3 of the
Chicago Area Transportation Study of 1959 as a reminder that technology hasn’t moved on as much as we think – their ‘Cartographatron’ was capable of mapping over 10 million commuting flows even then (though it was the size of a small house and required a team of technicians to operate it – see bottom of post for a photo).
 |
| Are you part of the big blue blob? |
Anyway, to the point… What’s the best way of mapping polycentricity in an urban region? For this, I decided to look at the San Francisco Bay Area since it has been the subject of a few studies by one of my favourite scholars,
Prof Robert Cervero of UC Berkeley. Also,
a paper by Melanie Rapino and Alison Fields of the US Census Bureau identified the Bay Area as the region with the highest percentage of ‘mega commuting’ in the United States (traveling 90 or more minutes and 50 or more miles to work). Therefore, I decided to look at commuting flows between census tracts in the 9 counties of the Bay Area, from Sonoma County in the north to Santa Clara County in the south. I’ve used a cut-off of 30 miles here instead of the more generous 50 mile cut-off used by Rapino and Fields. I also mapped the whole of the United States in this way, but that’s for another day.
The series of maps below illustrate both patterns of commuting in the Bay Area and the different approaches I’ve taken in an attempt to capture the essence of polycentrism in the area. I don’t attempt to capture the misery of some of these commutes, since for that I’d need a different kind of technology. But, I do think the animations in particular capture the polycentric nature of commuter flows. If you’re represented by one of the dots in the images below, thanks a lot for taking part!
Let’s start with a simple representation of commutes of over 30 miles from San Francisco County (which is coterminous with the City of San Francisco). The animated gif is shown below and you can click the links to view the sharper video file (mp4) in your browser (so long as you're on a modern browser). The most noticeable thing here is the big blue blob© making its way down from San Francisco to Palo Alto, Mountain View and Cupertino in Santa Clara County. In total, the blue dots represent just over 15,000 commuters going to 803 different destination census tracts. I’m going to take a wild guess and suggest that some of these commutes are by people who work at Stanford, Google and Apple. But it probably also includes people working at NASA Ames Research Center, Santa Clara University and locations in San Jose.
 |
| View video file in browser - or click image to enlarge gif |
These patterns aren’t particularly surprising, since there has been a lot of press coverage about San Francisco’s
bus wars and commutes of this kind. However, there is a fairly significant dispersal of San Francisco commuters north and east, even if the numbers don’t match those of the big blue blob. By the way, from San Francisco it's about 33 miles to Palo Alto, 39 miles to Mountain View, 42 to Cupertino and 48 to San Jose.
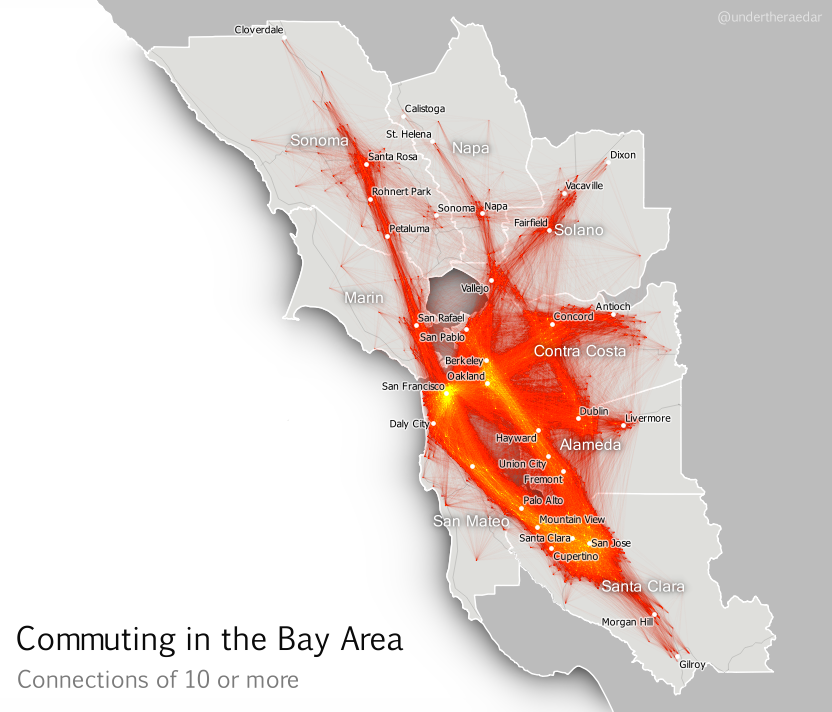
The first example above doesn’t reveal anything like the whole story, though. There are actually quite a lot of commuters who travel in the opposite direction from Santa Clara County to San Francisco but more widely the commuting patterns in the Bay Area – a metro area of around 7.5 million people – resembles a nexus of mega-commuting. This is what I’ve attempted to show below, for all tract-to-tract connections of 10 people or more, and no distance cut-off. The point is not to attempt to display all individual lines, though you can see some. I’m attempting to convey the general nature of connectivity (with the lines) and the intensity of commuting in some areas (the orange and yellow glowing areas). Even when you look at tract-to-tract connections of 50 or more, the nexus looks similar.
 |
| Click image to view larger version |
 |
| Stronger connections - click image to view larger version |
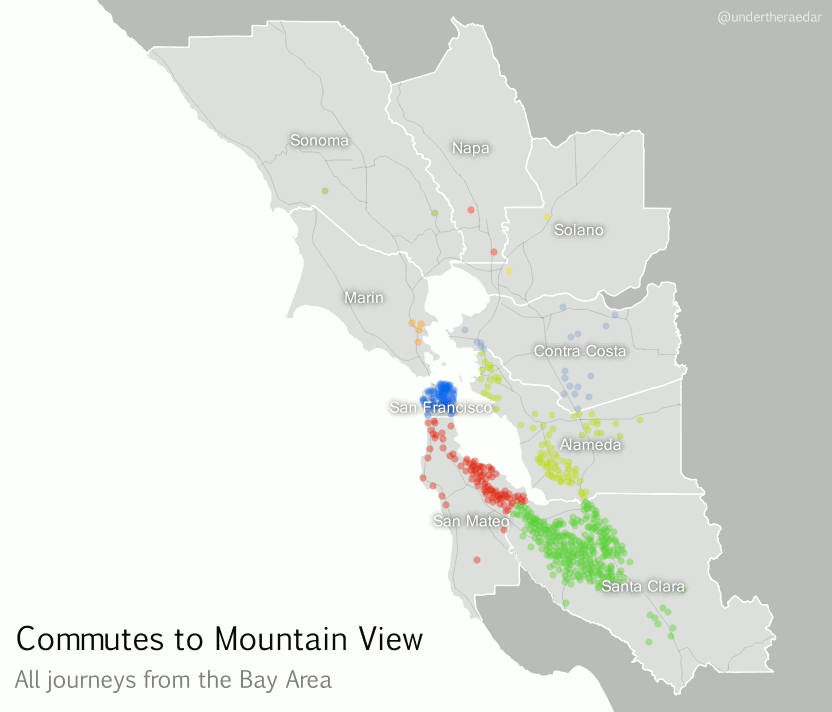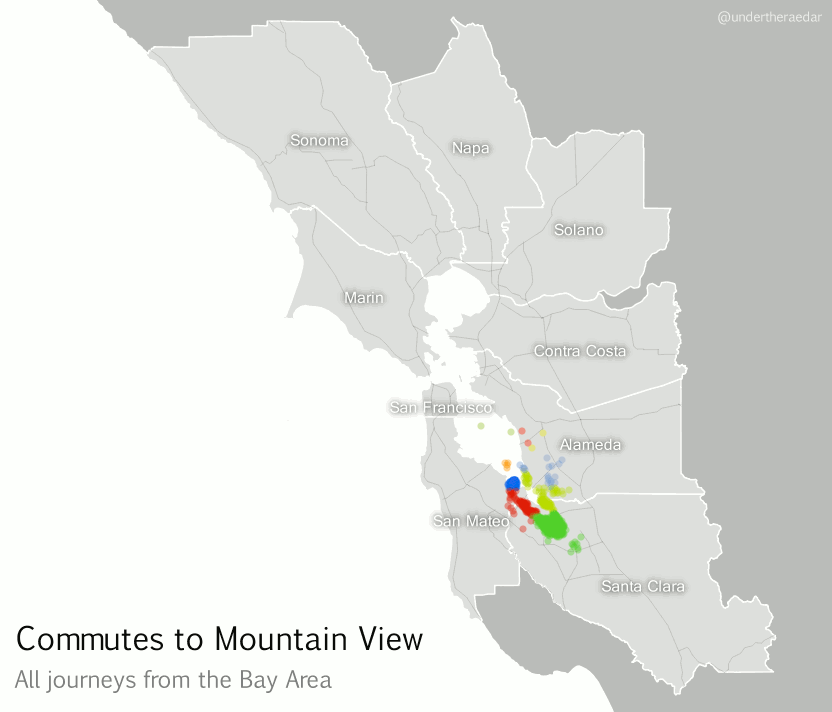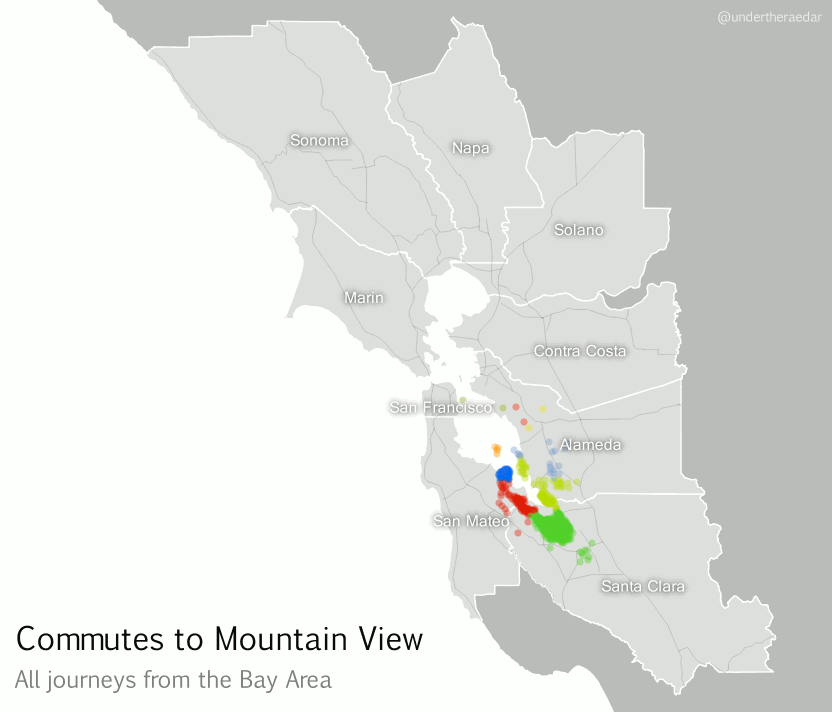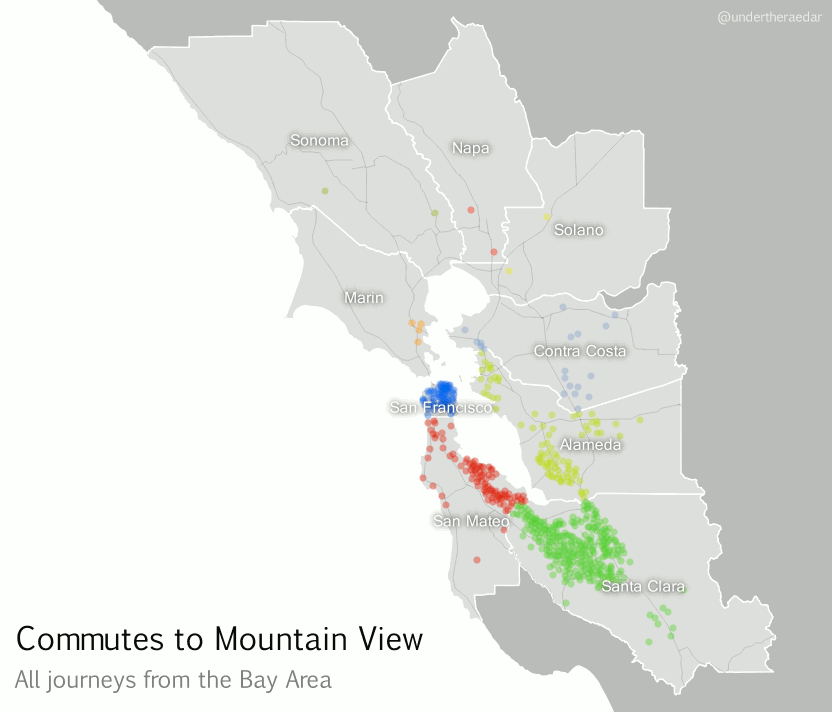
If we zoom in on a particular location, using a kind of ‘spider diagram’ of commuting interactions, we can see the relationships between one commuter destination and its range of origins. In the example below I’ve taken the census tract where the Googleplex is located and looked at all Bay Area Commutes which terminate there, regardless of distance. In the language of the seminal Chicago Area Transportation Study I mentioned above, these are ‘desire lines’ since this represents ‘the shortest line between origin and destination, and expresses the way a person would like to go, if such a way were available’ (CATS, 1959, p. 39) instead of, for example, sitting in traffic on US Route 101 for 90 minutes. According to the data, this example includes just over 23,000 commuters from 585 different locations across the Bay Area. I've also done an animated line version and a point version, just for comparison.
 |
| Commuting connections for the Googleplex census tract |
 |
| Animated spider diagram of flows to Mountain View |
 |
| Just some Googlers going to work (probably) mp4 |
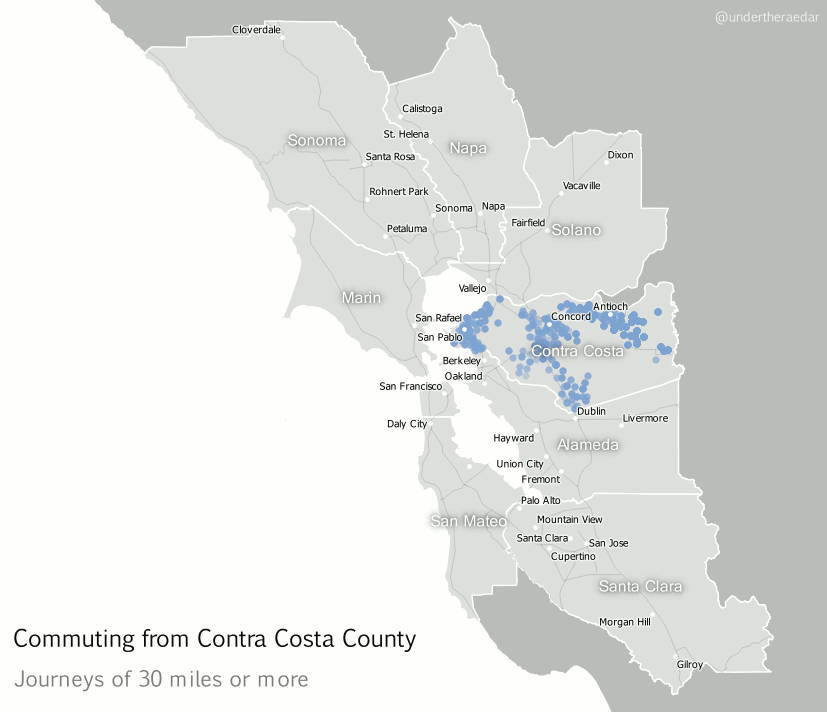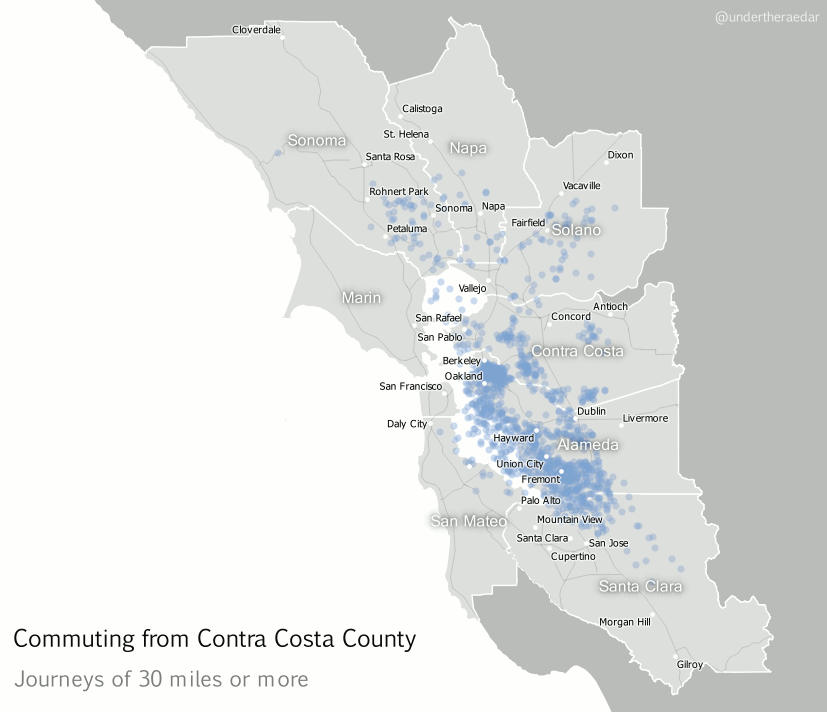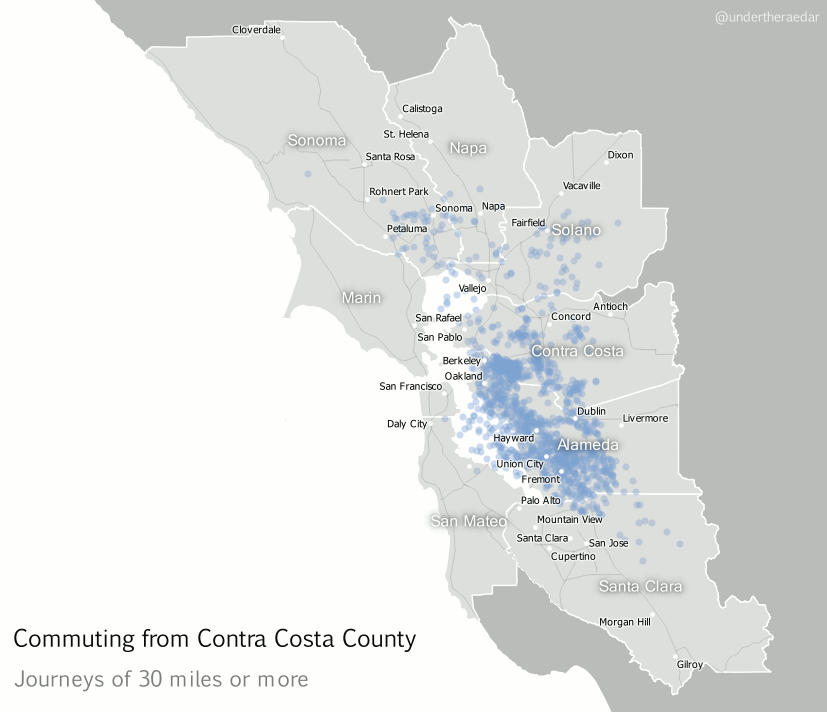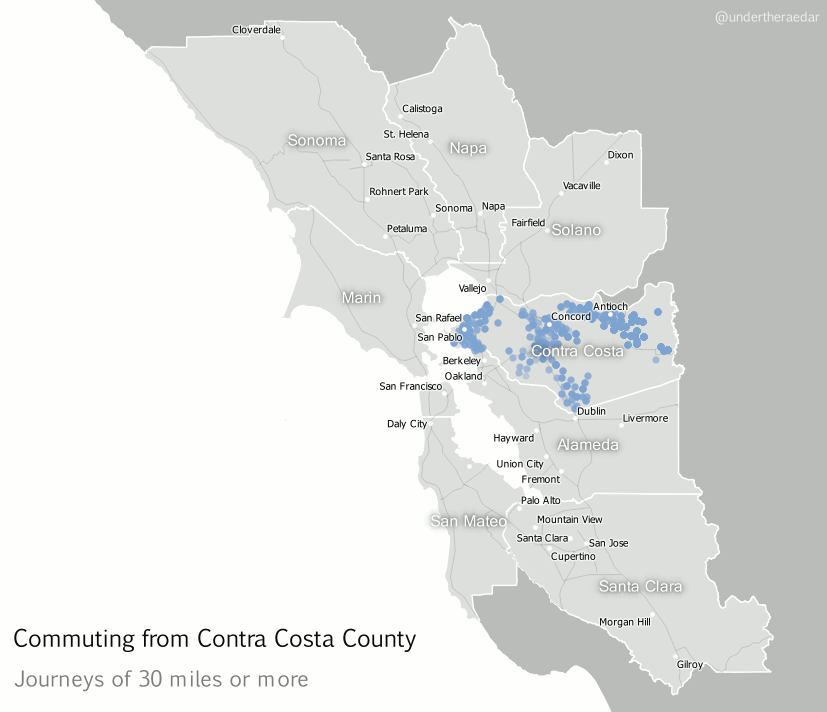
Looking further afield now, to different parts of the Bay Area, I also produced animated dot maps of commutes of 30 miles or more for the other three most populous counties – Alameda, Contra Costa and Santa Clara. I think these examples do a good job of demonstrating the polycentric nature of commuting in this area since the points disperse far and wide to multiple centres. Note that I decided to make the dots return to their point of origin – after a slight delay – in order to highlight the fact that commuting is a two way process. The Alameda County animation represents over 12,000 commuters, going to 751 destinations, Contra Costa 25,000 and 1,351, and Santa Clara nearly 28,000 commuters and 1,561 destinations. The totals for within the Bay Area are about 3.3 million and 110,000 origin-destination links.
 |
| Alameda County commutes of 30+ miles mp4 |
 |
| Contra Costa County commutes of 30+ miles mp4 |
 |
| Santa Clara County commutes of 30+ miles mp4 |
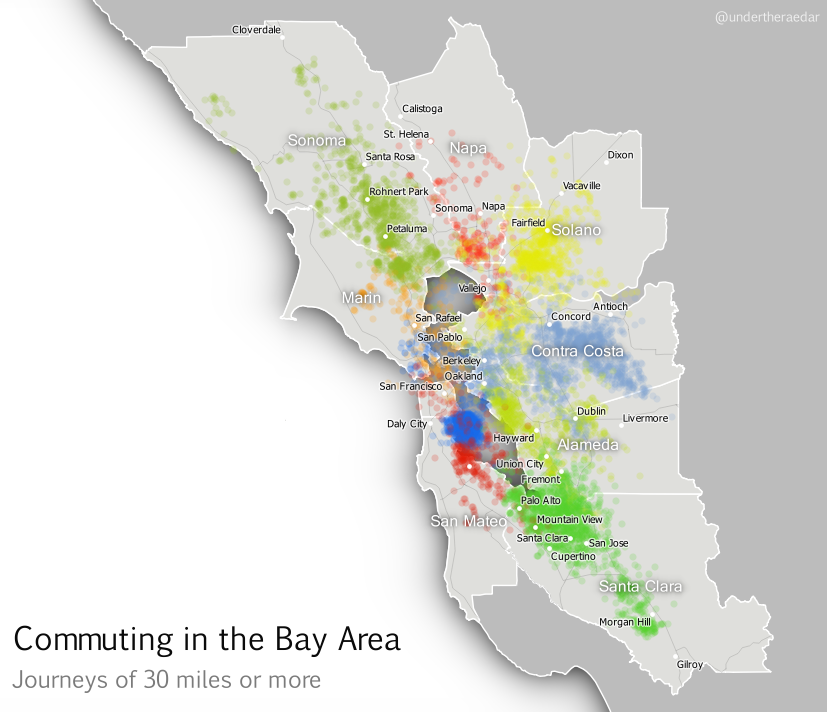
Finally, I’ve attempted something which is a bit much for one map, but here it is anyway; an animated dot map of all tract-to-tract flows of 30 or more miles in the Bay Area, with dots coloured by the county of origin. Although this gets pretty crazy half way through I think the mixing of the colours does actually tell its own story of polycentric urbanism. For this final animation I’ve added a little audio into the video file as well, just for fun.
What am I trying to convey with the final animation? Like I said, it's too much for a single map animation but it's kind of a metaphor for the messy chaos of Bay Area commuting (yes, let's go with that). You can make more sense of it if you watch it over a few times and use the controls to pause it. It starts well and ends well, but the bits in the middle are pretty ugly - just like the Bay Area commute, like I said.
My attempts to understand the functional nature of polycentric urbanism continue, and I attempt to borrow from pioneers like Waldo Tobler and the authors of the Chicago Area Transportation Study. This is just a little map-based experimentation in an attempt to bring the polycentric metropolis to life, for a region plagued by gruesome commutes. It’s little wonder, therefore, that a recent poll suggested Bay Area commuters were in favour of improving public transit. If you're interested in understanding more about the Bay Area's housing and transit problems, I suggest watching this
Google Talk from Egon Terplan (54:44).
Notes: the data I used for this are the 2006-2010 5-year ACS tract-to-tract commuting file, published in 2013. Patterns may have changed a little since then, but I suspect they are very similar today, possibly with more congestion. There are severe data warnings associated with individual tract-to-tract flows from the ACS data but at the aggregate level they provide a good overview of local connectivity. I used QGIS to map the flows. I actually mapped the entire United States this way, but that’s going into an academic journal (I hope). I used Michael Minn’s MMQGIS extension in QGIS to produce the animation frames and then I patched them together in GIMP (gifs) and Camtasia (for the mp4s), with IrfanView doing a little bit as well (batch renaming for reversing file order). Not quite a 100% open source workflow but that’s because I just had Camtasia handy. The images are low res and only really good for screen. If you’re looking for higher resolution images, get in touch. It was Ebru Sener who gave me the idea to make the dots go back to their original location. I think this makes more sense for commuting data.
The Cartographatron: Information and images on the 'Cartographatron' used in the Chicago Area Transportation Study (1959) are shown below.
 |
| From p.39 of CATS, 1959, Vol 1 |
 |
| From p.98 of CATS, 1959, Vol 1 |